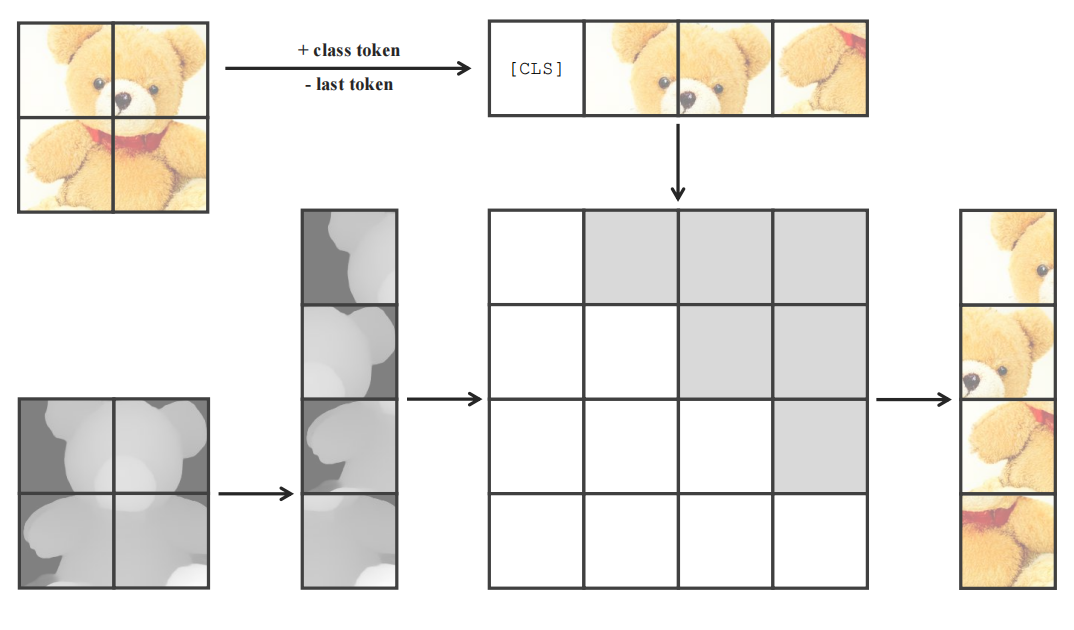
Controllable Generation
For controllable generation, we only need to replace the mask tokens used as the queries in the model with the condition tokens and align the queries with the targets.
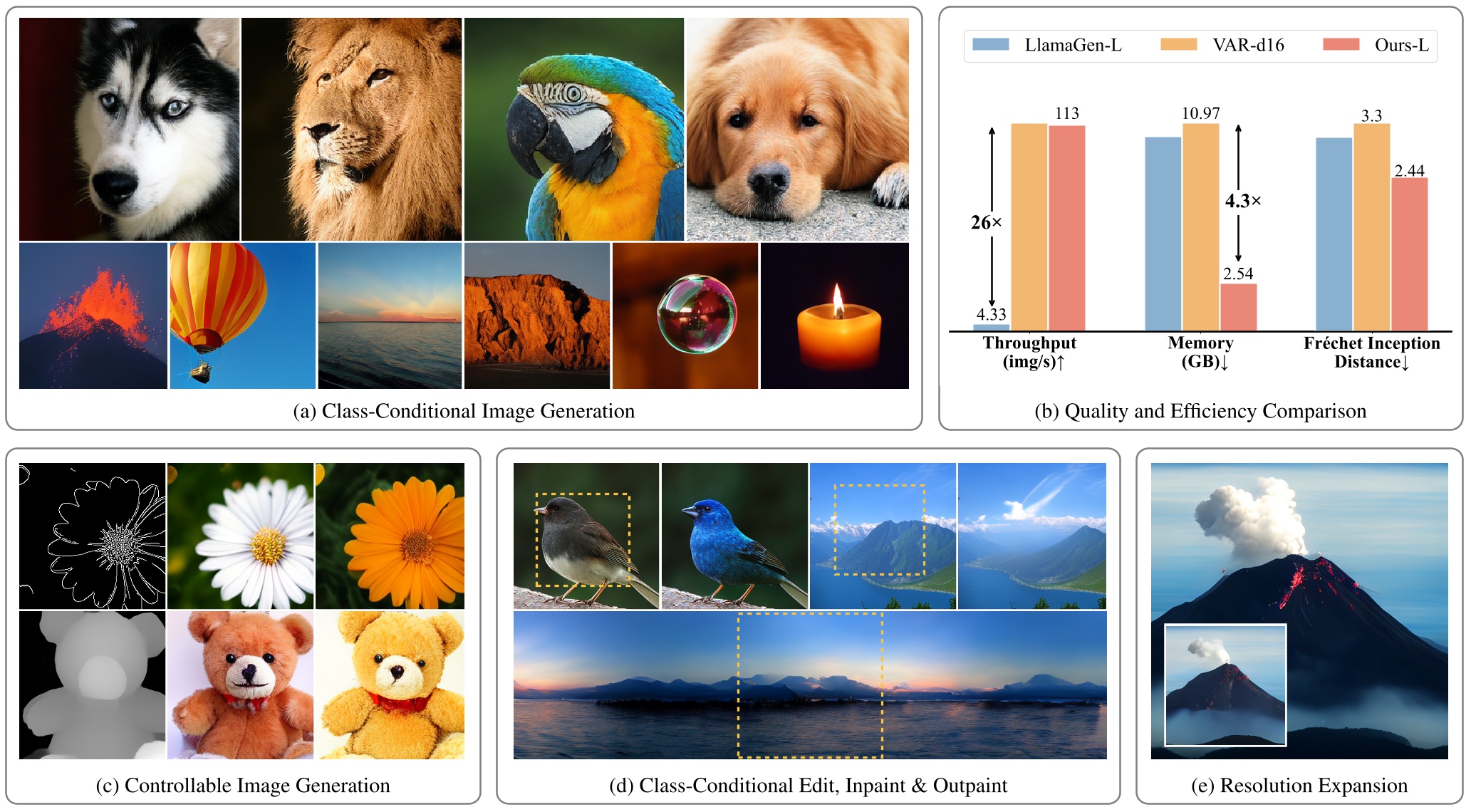
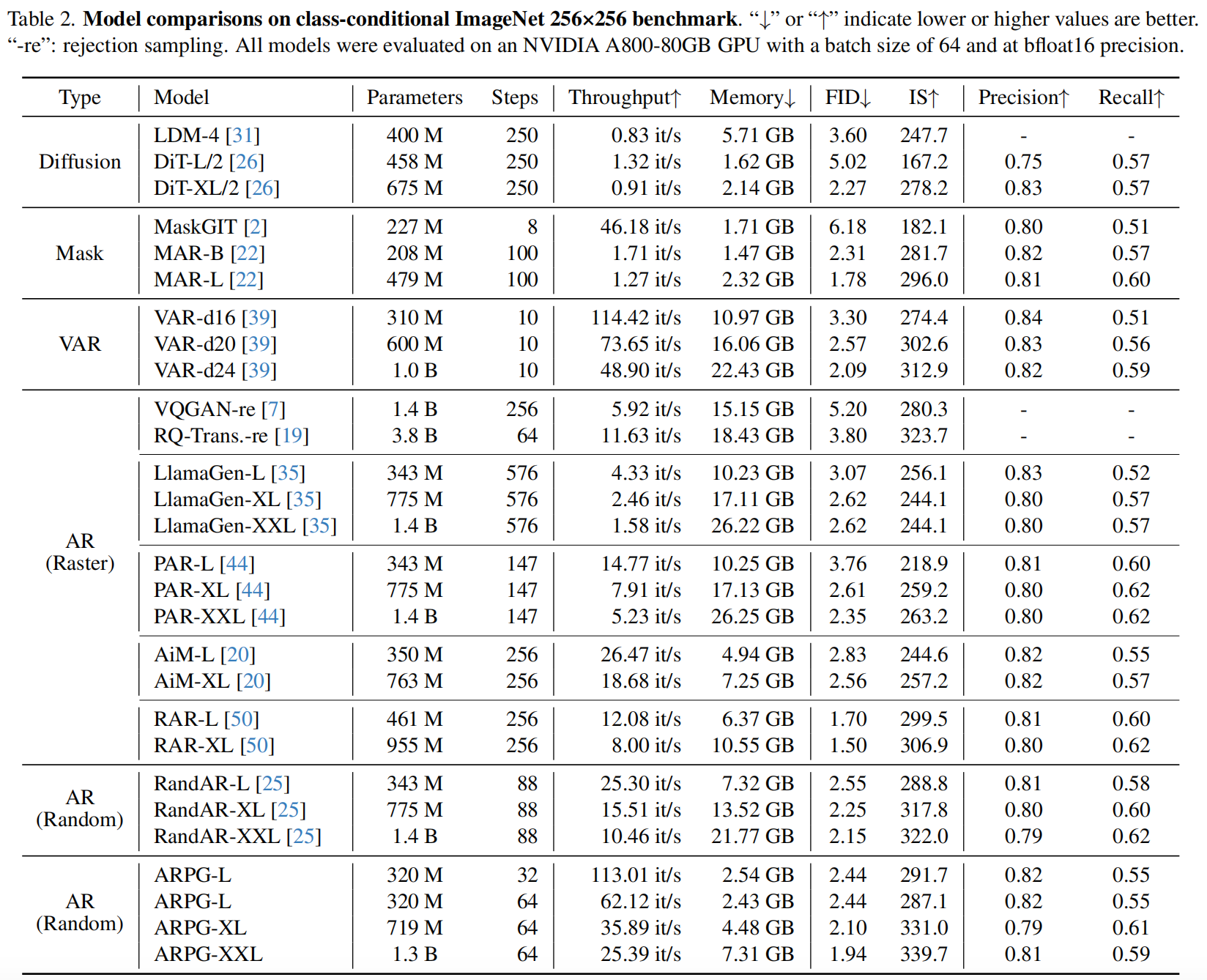
We introduce ARPG, a novel visual Autoregressive model that enables Randomized Parallel Generation, addressing the inherent limitations of conventional raster-order approaches, which hinder inference efficiency and zero-shot generalization due to their sequential, predefined token generation order. Our key insight is that effective random-order modeling necessitates explicit guidance for determining the position of the next predicted token. To this end, we propose a novel guided decoding framework that decouples positional guidance from content representation, encoding them separately as queries and key-value pairs. By directly incorporating this guidance into the causal attention mechanism, our approach enables fully random-order training and generation, eliminating the need for bidirectional attention. Consequently, ARPG readily generalizes to zero-shot tasks such as image inpainting, outpainting, and resolution expansion. Furthermore, it supports parallel inference by concurrently processing multiple queries using a shared KV cache. On the ImageNet-1K 256×256 benchmark, our approach attains an FID of 1.94 with only 64 sampling steps, achieving 26× faster in throughput while reducing memory consumption by over 75% compared to representative recent autoregressive models at a similar scale.
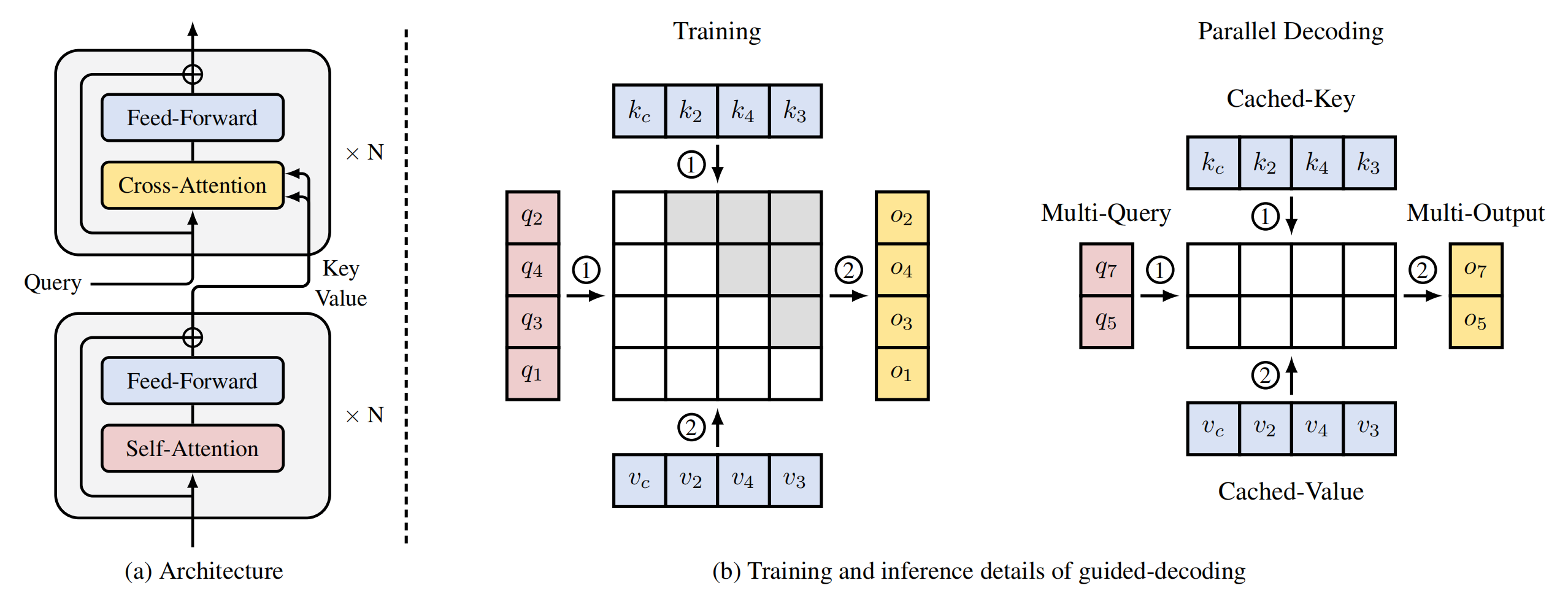
We employ a Two-Pass Decoder architecture. In the first pass, N self-attention layers extract contextual representations of the image token sequence as global key-value pairs. In the second pass, N cross-attention layers use target-aware queries that attend to these global key-value pairs to guide prediction. During training, the number of queries matches the number of key-value pairs. Each key's positional embedding reflects its actual position, while each query's positional embedding is right-shifted to align with its target position. During inference, multiple queries are input simultaneously, sharing a common KV cache to enable parallel decoding.
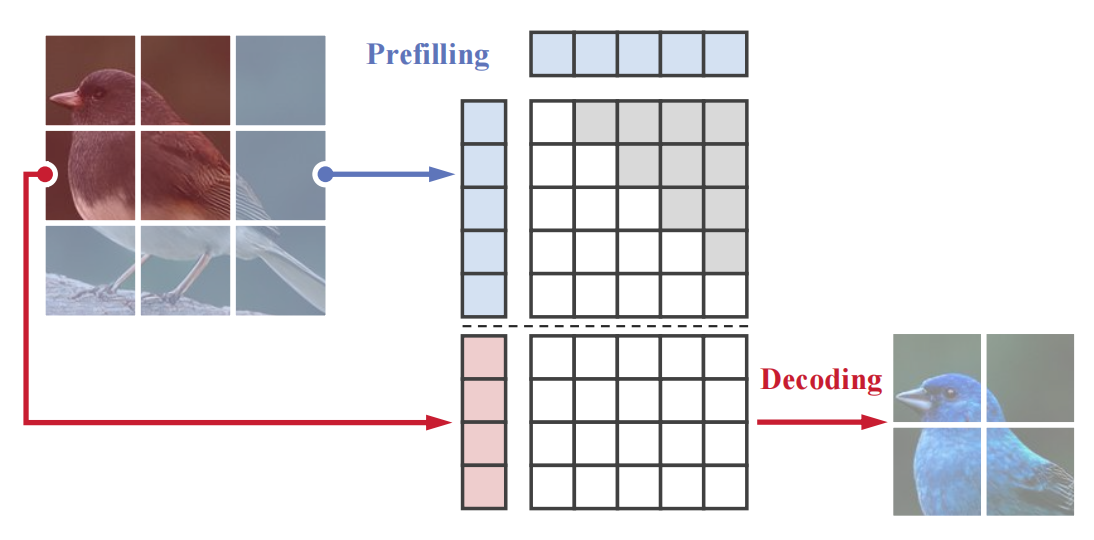
For controllable generation, we only need to replace the mask tokens used as the queries in the model with the condition tokens and align the queries with the targets.
We prefill the KV cache with all tokens from the non-repaint regions along with a class token. Tokens in the repaint regions are then replaced with mask tokens, which are used to generate image tokens based on the prefilled KV cache.



@article{li2025autoregressive,
title={Autoregressive Image Generation with Randomized Parallel Decoding},
author={Haopeng Li and Jinyue Yang and Guoqi Li and Huan Wang},
journal={arXiv preprint arXiv:2503.10568},
year={2025}
}